Stripe CTF v2.0 Level 8 Technical

Stripe CTF 2.0 ended this Wednesday after running for a week. The challenge consisted of 8 mostly web-based levels, and though I had plenty of fun ordering premium waffles to be delivered to my coordinates via quadrotor, this post is entirely about the eighth and final round.
The final round of CTF 2.0 was brute-force and consisted of a password verification server and four chunk verification servers. When a client connected to the password verification server to check a password, it split the password into chunks, connected to each of the chunk servers in sequence until one of them rejects the chunk. At that point, the password server sends a response to the client, and POSTs the same response to a set of webhooks. The solution took advantage of the server using sequential port numbers to send requests from, so the more correct chunks, the more port numbers were used. Webhooks were leveraged to check how many connections were made, by remembering the ports that they were sent from.
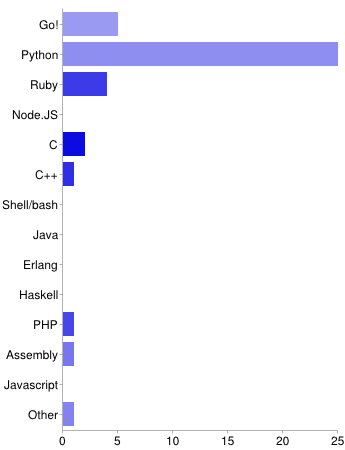
I did my best to crowdsource a list of Level 8 solvers, though if yours isn't on the list, please add it! Python was definitely the most popular language, while Google Go and Ruby share a much lower (and close) second place. A few poor souls attempted solutions in PHP and Assembly, and if you throw in C[++] and Perl, that's basically all of the languages that were submitted as of when I wrote this post.
The Stripe CTF servers were getting hit hard for most of the event, and hence were very slow. I decided to try running my own server to run against. I'm not a Python guy, though, so I decided to try writing my own password server instead (also partially because of lulz). I'll blog more on that project, FlagServ, in a later post.

All of the faster implementations did basically the same thing, except some tried from 000, 001, 002 . . . up to 999, while others picked a sequence of random numbers to test. Neither of those algorithms had and real advantage over the other, as it basically becomes a lottery as the speeds that our scripts ran.
Network lag is what kept the solvers from going mind-numbingly fast. A script running from localhost against FlagServ can capture a reasonable flag within a second, while remote solvers tend to take a minute or two to run. Thus, persistent connections and pipelining were huge pluses to quickly brute-forcing a flag. The other thing that mattered -- and the part requiring the most testing and thinking -- is reducing the number of requests that you need to make in order to accept or reject a certain choice. The port numbers returned don't always line up perfectly, as other things on the server use sockets. I recreated this so-called "jitter" in my custom level8 server using some calls to rand() to keep things interesting. Some scripts just check each possibility 5 or 10 times and see how many of the tries look good or bad. Though reliable, such a setup is not good at all for speedruns.
My personal solving script (which is really slow out of the speedrun scripts, btw) handles jitter in a somewhat naïve fashion. Every number that it tries is checked up to 5 times until it equals the target port delta for no chunks correct (which is 2). If it hasn't gotten a 2 after 5 tries, then it counts the number of 3s it got: if there's 3 or more, then that is used as the correct value of the chunk. With a naïve system like that, it's very easy to skip numbers, and also possible to get false positives. Luckily, false positives are easy enough to catch when messing with deltas: you know how many chunks are right whenever you get a delta, so if less are right than you think are right, you mis-guessed somewhere.
The last chunk can be one of the fastest, depending on how the solver is implemented. If no webhooks are requested, then FlagServ becomes ridiculously fast at handling processes. Speedsolvers regularly get the last chunk in a second or two once they drop the webhook.

After you look at it the solutions a bit, there's not really many other areas that mattered when it comes to speed; as long as everything works, your limits are based almost entirely on latency, "jitter", and how many requests your algorithm needs to use to check each value.
As to how long a capture takes, that comes down to how long it takes for your script to come across the correct numbers.